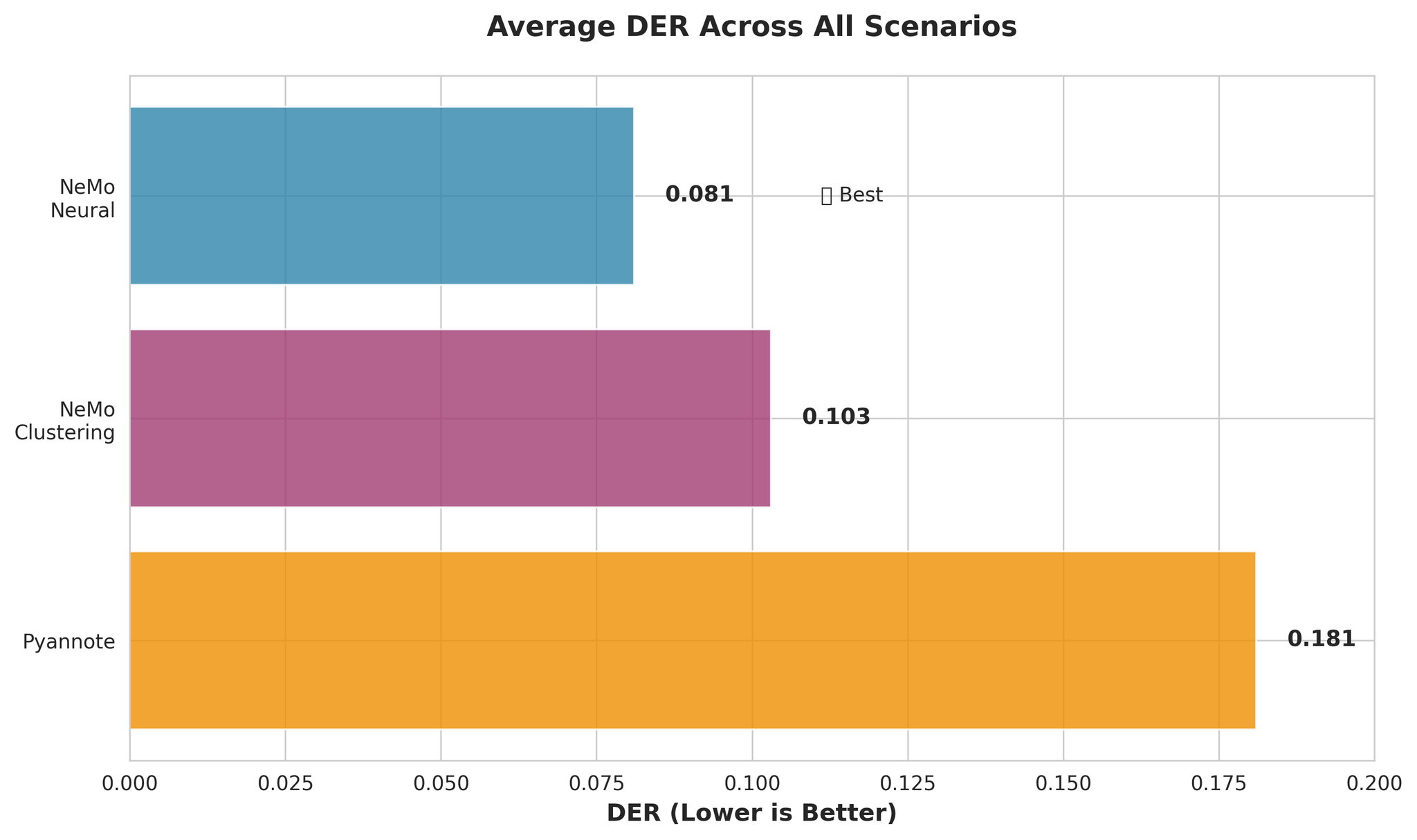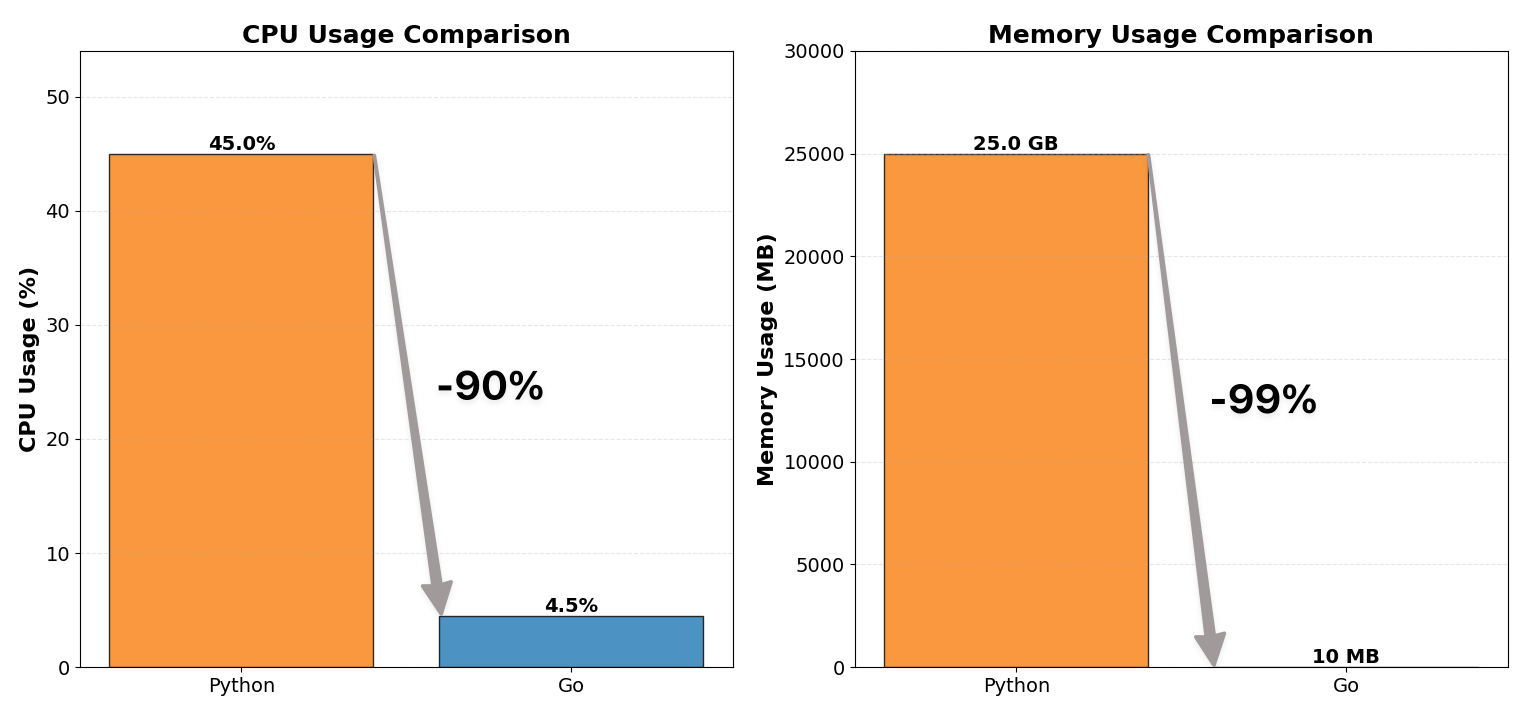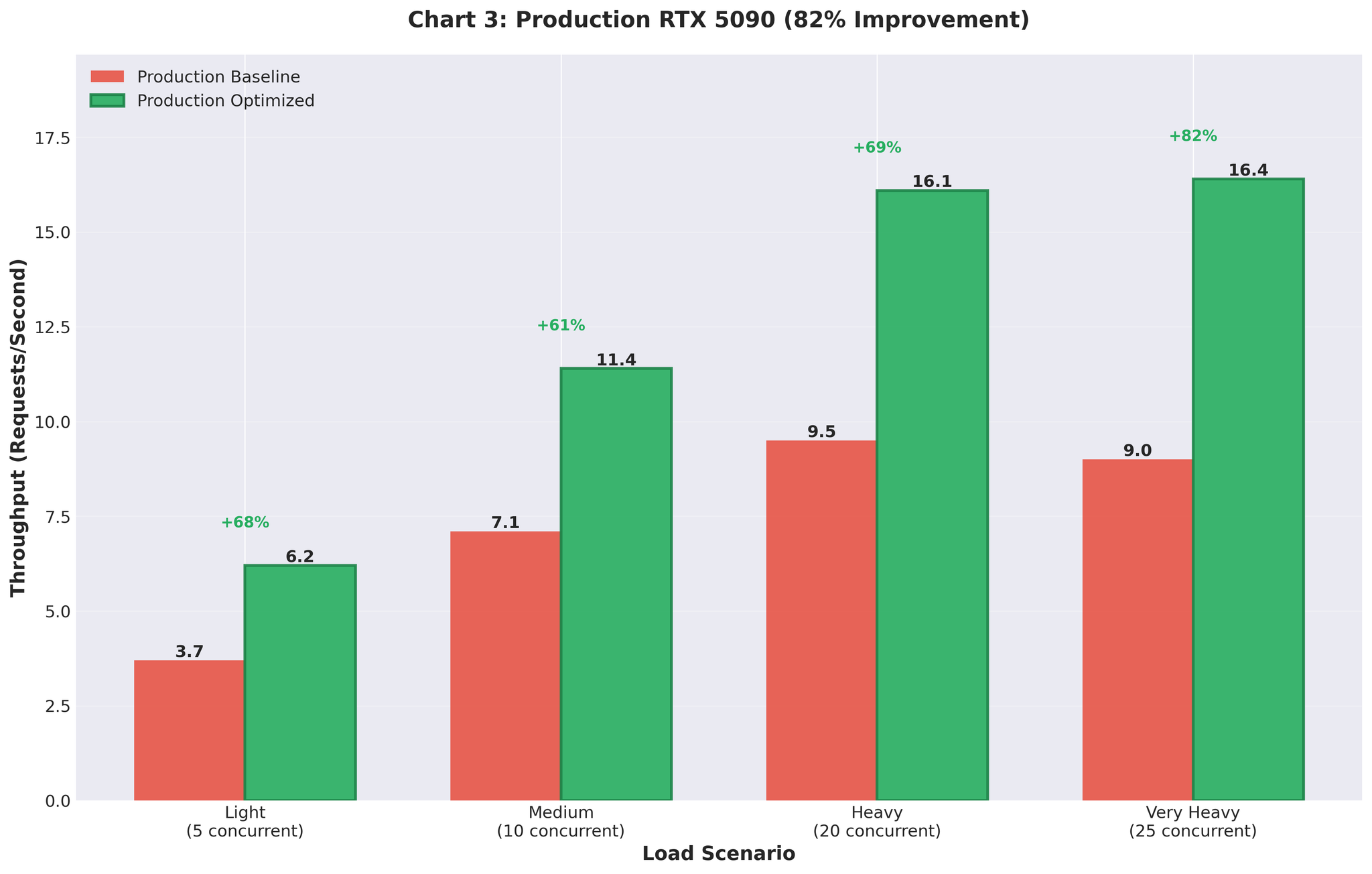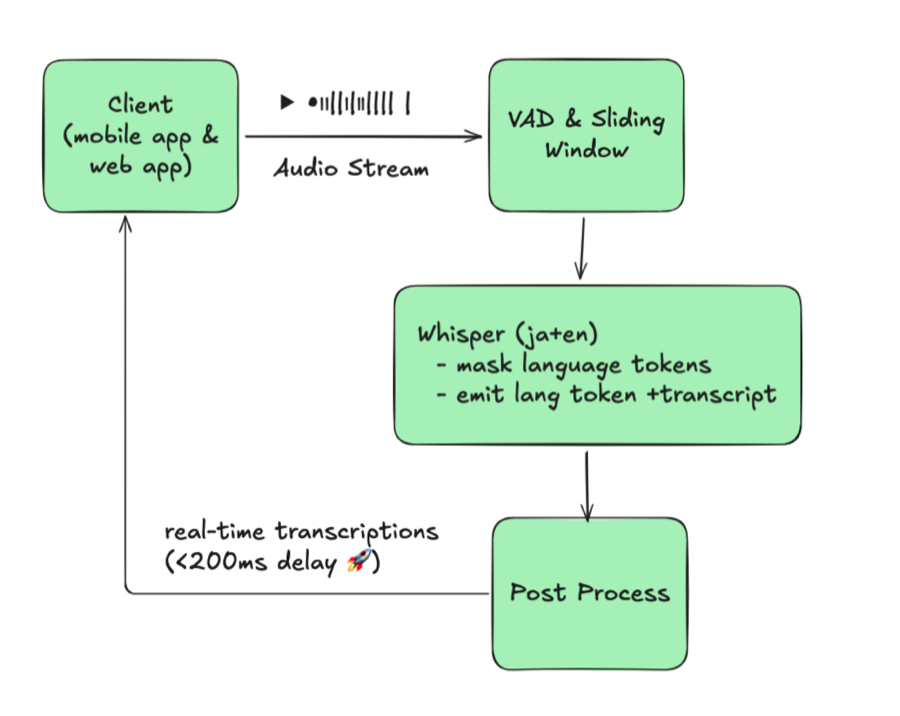
ASR
Whisper
Whisper in Production: Real-Time Dual-Language Switching, the Failures We Hit, and the Architecture That Works
How VoicePing engineered Bilingual Mode for automatic, low-latency language switching inside a single WebSocket stream powered by customized Whisper V2 models.
Akira Noda - VoicePing
9 min